Author:
Markus Levy of EEMBC and Rob Cosaro of Freescale
Date
09/02/2015
 PDF
PDF
The Internet of Things (IoT) represents a class of devices referred to as edge nodes; these require a battery life ranging from weeks to months to decades. An edge node typically contains a microcontroller to perform processing (e.g. encryption, compression, error correction, protocol stack), in addition to a transducer and radio component for communications. The IoT system designer must carefully select the microcontroller to ensure that it will meet the performance and energy requirements to enable the expected battery lives of their devices (of course, this is true of most ultra-low power applications).
In general terms for any industry-standard benchmarks, the key goal is to specific enough details in order to allow a system designer to make apples-to-apples comparisons. As a first step in understanding benchmarks for ultra-low power (ULP), consider the variety of implications. In some cases, the lowest active current is required when the power source is severely limited (e.g. energy harvesting). Alternatively, the lowest sleep-mode current is required when the system spends most of its time in standby or sleep mode, waking up infrequently (periodically or asynchronously) to process some task. Furthermore, ULP can also imply energy efficiency, whereby most work is performed in a limited time period.
Setting benchmarks
Overall, a benchmark that attempts to mimic real-world applications will require a combination of, or tradeoffs on, each of the above implications. To satisfy these fundamental requirements, EEMBC established ULPBench to provide a consistent method to measure energy efficiency for general-purpose ultra-low power applications, demonstrating both active power and idle (sleep) power capabilities.
The next step in deriving this benchmark was to determine the workload that should be used when deriving the energy specification. Equally as important was determining the duty cycle (duty cycle equals Active time/total time) to represent the transitions from active to low power state. Finally, and different from a standard performance benchmark, ULPBench needed an integrated hardware aspect to accurately measure the energy consumption. Hence, the consortium produced EnergyMonitor, a USB-powered power supply for the target device under test (DUT). It connects to a device under test through a 100mil, 2-pin header and both supplies and measures the energy to power the DUT.
EEMBC is extending ULPBench to represent a variety of IoT edge-node applications requires adding in a sensor element, potentially higher degrees of computation (e.g. encryption, data analysis) as well as a communication strategy (e.g. Bluetooth Smart or ZigBee). Fundamentally, both approaches have specific duty cycles in which they transition between active and low-power modes (see Figure 1).
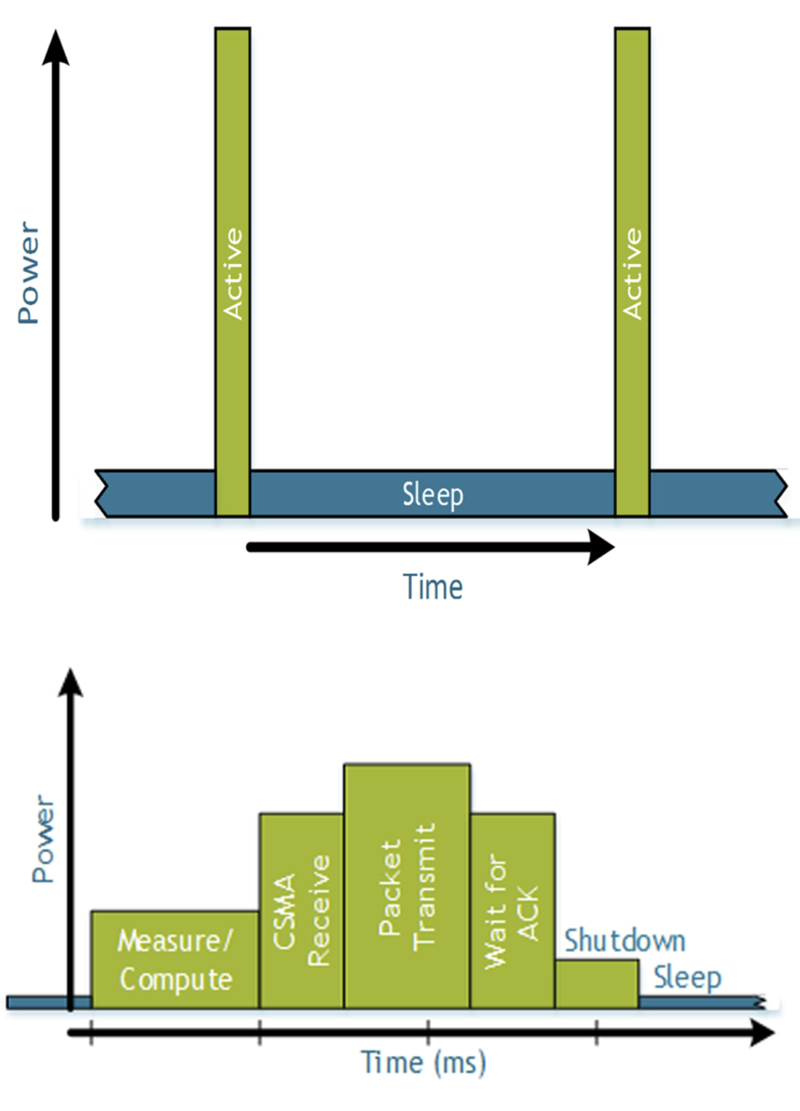
Click image to enlarge
Figure 1. Highlighting the difference between the basic ULPBench (top graph) and an IoT profile using ZigBee
While industry-standard benchmarks allow the user to select the most optimal components for a given set of tests, they are not the end all for optimizing a system design. As a first step, the system designer should understand the strategy associated with duty cycles. The ultimate design goal should be to minimize the active current and get the MCU into its deep sleep mode as quickly as possible.
Minimizing active current and effectively using deep sleep modes of a microcontroller makes sense in optimizing overall system energy use. However, what are the trade-offs between microcontroller choices and what’s the impact of the application’s duty cycle and deep sleep currents on that energy? The energy per cycle, as a function of duty cycle D, is defined by a simplified equation which assumes the energy in the on and off transitions are small.
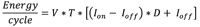
; where the slope is defined by Ion since Ioff is much smaller than Ion and the y intercept is just Ioff. This equation can help comprehend what duty cycle is the on current more important than the off current. Figure 2 shows a graph of the energy difference with an on current fixed at 5mA an varying off currents. Above duty cycles of around 0.07, there is only a 5% difference in energy per cycle when the off currents are less than 20μA. These curves give an insight on the tradeoffs between duty cycle and off currents
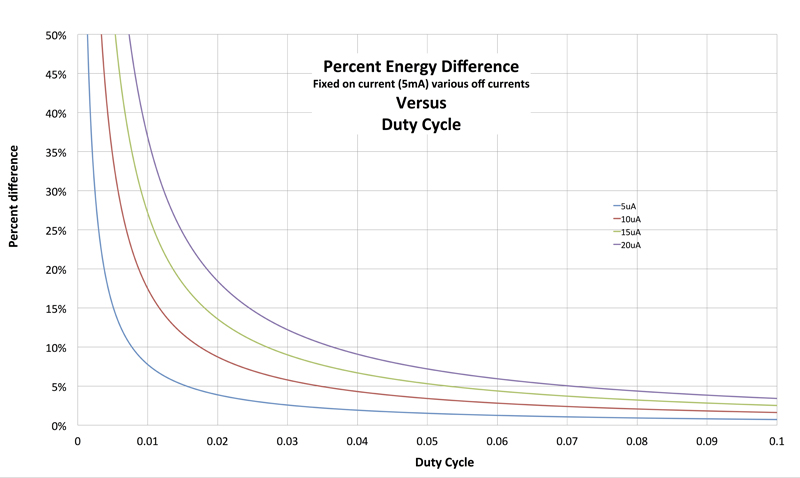
Click image to enlarge
Figure 2. Percent energy difference as a function of duty cycle
Where does ULPBench fit in as a workload for the microcontroller? For an ARM Cortex M0+ and Cortex M4, ULPBench takes approximately 14253 cycles and 11852 cycles, respectively. This difference represents a 17 % difference in the number of cycles, but depending on the implementation, an M4 can consume more than twice the power. Table 1 shows the ULPBench duty cycle for M0+ and M4. The duty cycles for ULPBench show that the off current makes a big difference in the score, and that M4 does not offer significant advantages in reducing the time it takes to complete the benchmark, so in general M0+ should yield better ULPBench results.

Click image to enlarge
Table 1 ULPBench duty cycle for M0+ and M4
The graph in Figure 3 shows the difference between off currents of 1μA and 5μA, where the arrows show the range of duty cycles ULPBench occupies. It is clear from the figure that off-current changes make a large difference in the score.
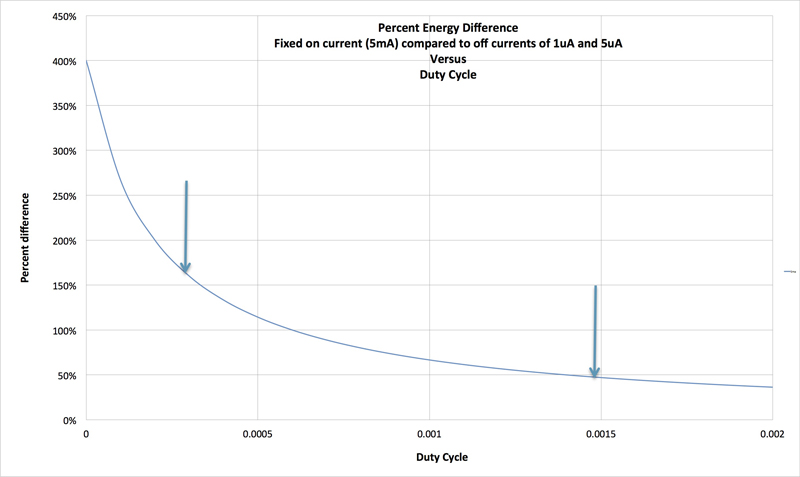
Click image to enlarge
Figure 3. Percent difference in energy for a fixed 5mA on time current comparing off currents of 1uA and 5uA.
Apply it to the app
Having an industry-standard benchmark is important for comparing microcontrollers, but it is just as important to understand the benchmark’s functionality and how it relates to the ultimate application. For example, running an inertial platform algorithm on an M4 and an M0+, the M4 is about 15 times more energy efficient than the M0+ (see Table 2).

Click image to enlarge
Table 2 Cycles and energy to complete an inertial platform algorithm
Further optimizations for ultra-low power IoT applications can be achieved by clever optimizations that utilize the microcontroller’s feature set. For example, Figure 3 depicts a sequence of optimizations steps that can significantly improve energy efficiency in a typical IoT edge node. In each of the three scenarios, there are four tasks - specifically two tasks for reading sensors, one task for processing the sensor data, and the final task for transmitting the data.
In the first scenario, the processor is active throughout the duration of the four tasks, followed by a period where the MCU is in a sleep mode. When the processor is used for all of the tasks, it consumes the most current. Although this is the easiest way to implement an application, since it only relies on the processor, the processor is always running code and is continually accessing RAM and Flash.
There’s an intermediate scenario (not shown) where the processor is active only when processing the sensor data. During the other three tasks, the processor is put into a low power mode and polls the peripherals, collecting data at low frequencies using the processor’s very low power modes to save significant energy.
The third scenario realizes additional energy savings by utilizing the DMA engine, while allowing the processor to remain in its very-low-power-wait (VLPW) mode. Each task is performed serially before the MCU can enter its deep sleep mode. DMA engines use much less power than the processor since they are smaller and do not have to continuously access RAM and Flash. For example, with the Kinetis K22F, the DMA engines will consume less that one fifth the current of the processor doing the same task.
In the definitive optimized scenario, the sensor read and transmit tasks can be arranged in parallel, thereby getting the MCU very quickly into its deep sleep mode. The more functions that can be done in parallel, the sooner the microcontroller can return to deep sleep mode. For the K22F, the DMA engines have linked channels. This means the DMA engine can do both transmit and receive operations without having the processor involved with the operations. In addition, the multiple channels can deal with transmitting and receiving blocks of data from several peripherals simultaneously.
Going from the scenario with no optimizations to polling and utilizing the VLPR mode, the microcontroller energy consumption dropped by more than 2000 times (at 48MHz, from 3.56 down to 0.00165 milliJoules). Utilizing serial DMA resulted in a further drop of 1.5 times (from 0.00165 down to 0.0011 mJ). Finally, utilizing parallel DMA, we witnessed an additional drop of 1.5x (from 0.0011 to 0.00057 mJ).
As we’ve discussed, the industry-standard ULPBench is a good starting point for comparing and understanding the behavior of microcontrollers. However, a system designer must look at all implementation details in order to maximize a device’s energy efficiency. This includes things such as the duty cycle of active versus sleep mode, as well as optimizing peripheral utilization. Looking into the future, EEMBC will expand the functionality of ULPBench to account for peripheral functions, such as DMA.



