Signal integrity and reliability in the mission-critical power industry
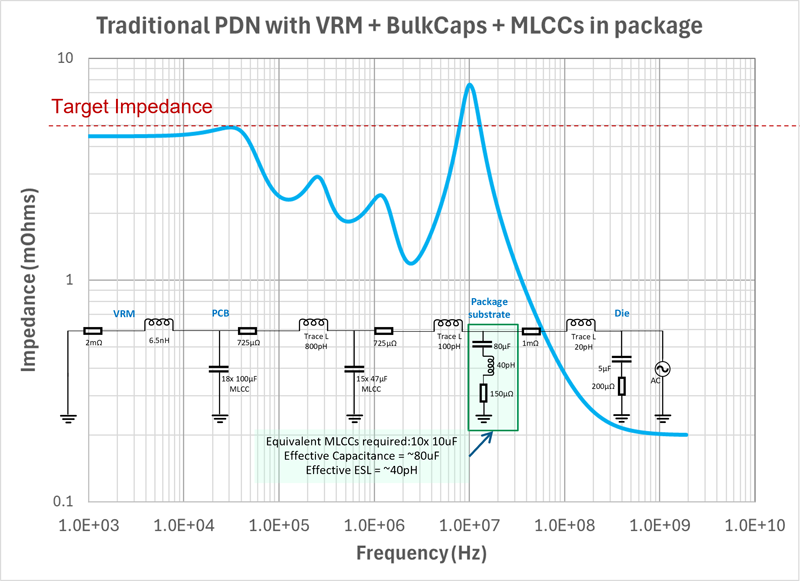
Ruggedized, Fast/Gigabit Ethernet rack-mount switches, such as this Hirschmann MACH1000, offer high port density and hundreds of copper/fiber media-mix options, excellent RFI/EMI shielding, and high performance - even in the harshest industrial environments and applications
Today's power grid receives energy from conventional, independent and alternative power source producers and distributes that power to industrial, commercial and residential customers. Providers must keep power flowing at peak efficiency, ensuring the electrical grid always closely matches power outflows. This kind of mission-critical performance relies on reliable, real-time signal transmission, which in turn must be built upon a strong and reliable data communications infrastructure. For power companies, performance and reliability are top-of-mind issues. Given the $150 billion price tag industry studies estimate are incurred within the industry as a direct result of power outages, any unexpected failure of a data network can be catastrophic. Failure of mission-critical network components - whether hardware or cables - can result in signal disruptions that can lead to power outages, unhappy customers and escalating repair and service costs. Redundancy Provides a Solution Signal transmission redundancy is critical for any network requiring continuous operation and high availability. For "always-on" power suppliers, as well as many manufacturers and processors, redundancy is an upfront investment that can pay for itself many times over by mitigating the risk of unplanned outages and ensuring continuous operations. A redundant network instantly provides alternative pathways for signals to travel until the damaged components can be repaired or replaced. Network redundancy acts much like an insurance policy, protecting power organizations from disastrous results in the event of unexpected downtime - and enabling them to provide customers with the performance and reliability they expect and are paying for. Within a network infrastructure, redundancy is the best way to reduce the possibility that a single point of failure - such as a cable break or a switch or router malfunction - will disrupt communications. Properly implemented, network redundancy creates multiple data paths between any and all locations through which critical data flows. If a failure should occur, an alternative pathway automatically kicks in to maintain uninterrupted communication. Designing a Redundant Network The engineering team charged with creating or facilitating a redundant network framework for a power company must first formulate a plan designed to achieve the desired functionality, and then make informed choices regarding component selection and redundancy methodologies. Determining the right approach will depend largely on the applications and/or processes involved and the network topology already in place. Some key factors to consider include the location and physical layout of the system, and the environmental risks to the cabling, connectivity and switching devices required to implement the system. Given the mission-critical nature and harsh environments typical of the power industry, specifying environmentally hardened, industrial strength network components is paramount to long-term network performance and reliability. Other key factors to consider include: • Required protocol speed. How fast a recovery time does the application demand? • Physical layout of network components - How and where will the cabling runs be configured? A system covering a large geographic area might call for one kind of redundancy solution, while a more compact network might better accommodate another. • Probability of failure - An extremely harsh environment, for example, creates greater risk for network components and pathways. Such circumstances could very well suggest the need for more than one redundant path. • Green field or retrofit installation - In general, designing redundancy into a new installation will be easier and offer more flexibility than would be required to work around an existing network topology. In the latter situation, the legacy architecture must be accommodated, which can present design and installation challenges and add to the overall cost structure.

The Role of Managed Switches Networks employing redundancy must be equipped with managed switches, rather than unmanaged switches. Unmanaged switches are basically plug-and-play devices with no intelligence, so they are unable to support redundancy protocols. Managed switches, on the other hand, are intelligent devices that provide visibility into the network. Many employ link-loss-learn, a self-healing feature that simplifies and speeds recovery from a link fault or breakage. Immediately recognizing the broken link, the managed switch's internal mechanism prompt it to automatically flush its media access control (MAC) address label, alert the other switches within the redundant topology of the change, and then force the other managed switches to do likewise, thereby reducing recovery time to the sub-second level. Of course, a reporting or monitoring mechanism should be in place to alert personnel to the failure, so that it does not go undetected. Once the faulty component has been repaired or replaced, the system will automatically return to its normal state. Because managed switches are more complex than unmanaged switches, design engineers should select them carefully to ensure that they are designed to support the protocol being used and meet all application requirements, including data rates, power supplies, type of ports, and mounting options. Understanding and Specifying Redundancy Protocols Over and above network component selection, it is important to understand and consider the capabilities and requirements of the various redundancy methodologies available today. Redundancy protocols can be open, standards-based systems or proprietary systems. In general, standards-based protocols provide excellent interoperability, but slower recovery times, whereas proprietary protocols typically offer faster recovery times and is designed specifically for industrial recovery applications. The use of hybrid redundancy protocols - a mix of the two types - is fairly common. Two popular standards-based redundancy protocols include: • Rapid spanning tree protocols (RSTP) use algorithms to determine which data paths are used for primary communications, which are redundant, and which are the most reliable. This methodology is best suited for complex mesh network topologies with multiple redundant links, but can also be used in a ring topology. The downside is that RSTP is not scalable and recovery speed is one second or more, which may be problematic for some power processes. • Link aggregation provides a way to group multiple links into one virtual link. Say, for example, eight links are established between two locations. If eight 100-Megabit connections are in place, link aggregation will make them into one 800-Megabit connection. So, if one link malfunctions or fails, the system drops back to 700 Megabits but remains intact. Link aggregation is often used in tandem with RSTP methodology, but like RSTP, recovery speed is slow (one second or more). Two commonly used proprietary redundancy protocols include: • Ring protocols, which offer high availability, consistency and reliability. Ring protocols will not work with mesh topologies. They are, however, highly scalable. Single ring protocols of up to 200 switches have been tested and proven effective, and recovery times were fast and consistent. In fact, leading vendors of proprietary ring protocols are now offering recovery speeds of 300 milliseconds or less, with newer versions recovering at 10 milliseconds or less. • Dual-homing or redundant ring coupling is another variation, which typically offers recovery speeds in the 200 millisecond range. This approach can be used to provide redundancy to or connect a ring topology - either proprietary or standards-based - to enable redundant links between the ring, or between other lower level networks and a higher level network. A hybrid protocol might be a mixture of any of these methodologies. For example, a ring protocol might be used with smaller redundant mesh networks using rapid spanning tree connected to it. Several ring networks might be connected redundantly using the dual-homing/ring coupling protocol. Or, link aggregation might be used with either a rapid spanning tree or a ring solution. A communications system manufacturer or experienced systems integrator can be of great help to design engineers in specifying solutions that best meet their application requirements. Conclusion Clearly, redundant networks offer significant value, both from an operational and financial point of view. The primary benefit is the ability of redundancy to mitigate the risk of unplanned outages. With their intelligent capabilities and self-healing features, redundant systems add a critical layer of protection in always-on industrial operations. The investment in network redundancy is a small price to pay for the peace of mind this technology can deliver. www.belden.com