Creating Memories for Vehicles

Researchers at Cornell University have developed a way to help autonomous vehicles create “memories” of previous experiences and use them in future navigation.
One of the problems of designing software for autonomous vehicles is that they are in a continuous state of seeing the world for the first time. Unlike humans who see snow and instantly realise it will be cold and slippy, vehicles have to detect the snow and then rely on the sensors to feed the AI details of what conditions would be like before the AI starts to take action. The problem is that those sensors may not act optimally in adverse conditions, feeding misleading information to the vehicle’s AI. If autonomous vehicle could “remember” conditions and scenarios like we do, creating autonomous software would be much more simple and efficient.
Researchers at Cornell University have looked at this problem and developed a way to help autonomous vehicles create “memories” of previous experiences and use them in future navigation, especially during adverse weather conditions. The researchers have produced three papers on the subject, two of which were presented at the Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2022) on June 19-24 in New Orleans.
“The fundamental question is, can we learn from repeated traversals?” said senior author Kilian Weinberger, professor of computer science. “For example, a car may mistake a weirdly shaped tree for a pedestrian the first time its laser scanner perceives it from a distance, but once it is close enough, the object category will become clear. So, the second time you drive past the very same tree, even in fog or snow, you would hope that the car has now learned to recognize it correctly.”
Led by doctoral student Carlos Diaz-Ruiz, the group compiled a dataset by driving a car equipped with LiDAR sensors along a 15-kilometer loop in and around Ithaca, 40 times over an 18-month period. The traversals capture varying environments, weather conditions and times of day. This created a resulting dataset with over 600,000 scenes. The approach that the team developed is named HINDSIGHT. It uses neural networks to compute descriptors of objects as the car passes them. It then compresses these SQuaSH (Spatial-Quantized Sparse History) descriptions and stores them on a virtual map, like a “memory” stored in a human brain.
The next time the self-driving car traverses the same location, it queries the local SQuaSH database of every LiDAR point along the route and “remembers” what it learned last time. The database is continuously updated and shared across vehicles, enriching the information available to perform recognition. HINDSIGHT is intended to be a precursor to additional research the team is conducting, MODEST (Mobile Object Detection with Ephemerality and Self-Training), that would allow the car to learn the entire perception pipeline from scratch.
While HINDSIGHT still assumes that the artificial neural network is already trained to detect objects and augments it with the capability to create memories, MODEST assumes the artificial neural network in the vehicle has never been exposed to any objects or streets at all. Through multiple traversals of the same route, it can learn what parts of the environment are stationary and which are moving objects. Slowly it teaches itself what constitutes other traffic participants and what is safe to ignore. The algorithm can then detect these objects reliably – even on roads that were not part of the initial repeated traversals.
.jpg)
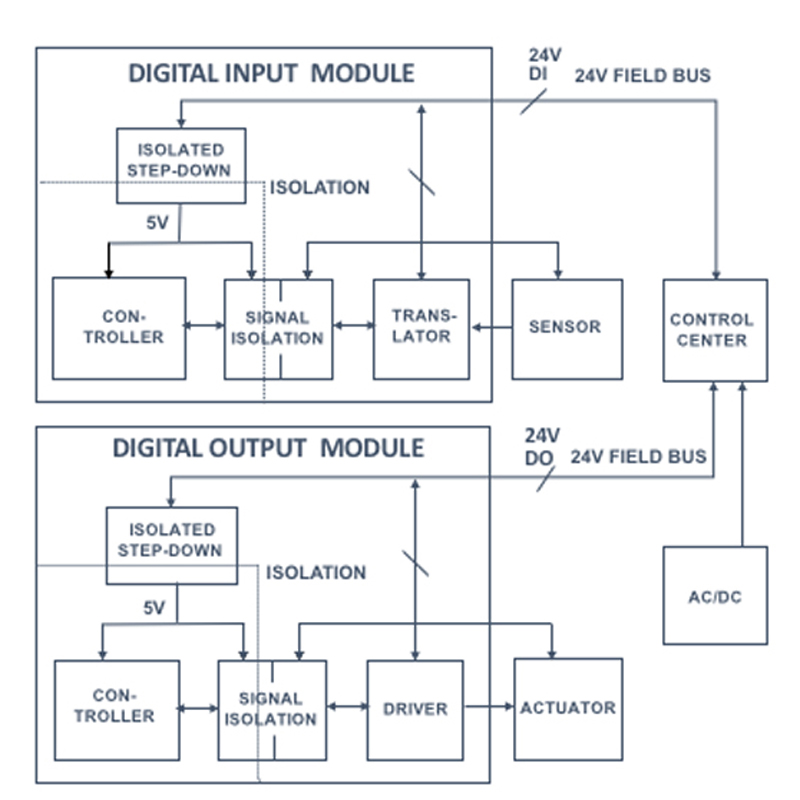
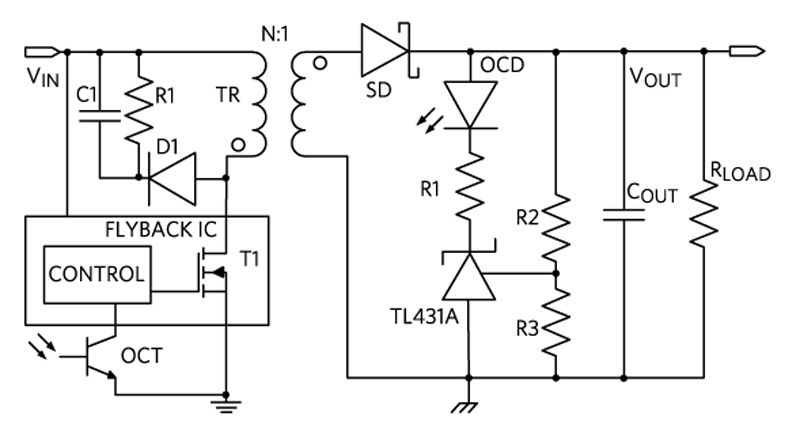
Accelerating Isolated Power Supply Design
05/10/2017
