Rapid evolution presents unique challenges for the data center power landscape
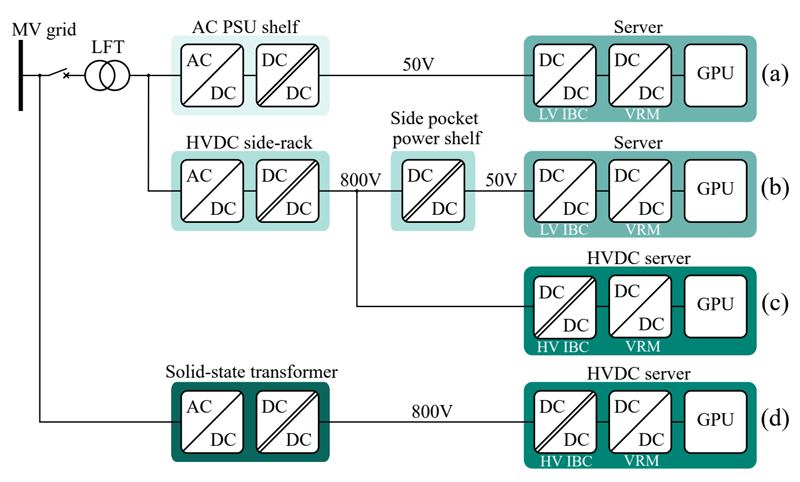
Figure 1: Modern computing demands more power, efficiency, and scalability, creating a shift toward higher voltage IT and power infrastructure in data centers
The continued evolution of artificial intelligence (AI), machine learning (ML), and large language models (LLMs) is fueling a global demand for more sophisticated and power-optimized data centers. Research by Goldman Sachs estimates that data center power demand will grow by 160% by 2030, driven largely by the capacity requirements of these emerging tools. By this same year, the Electric Power Research Institute (EPRI) estimates that data centers could grow to consume up to 9% of the United States’ annual electricity generation, up from 4% of the total load in 2023. And while the recent Deepseek announcements may dampen this consumption projection, typical patterns in technology advancements indicate that these applications’ energy consumption will still trend upwards.
This surge in demand presents significant challenges for data center operators. For one, they are tasked with expanding and upgrading their facilities to meet growing space requirements. They’re also tackling substantial power demands and determining how to efficiently address the heat generated by high-performance hardware. The rapid evolution of graphics processing units (GPUs) used for AI applications only adds to these concerns.
The numerous unknowns of AI and GPU implementation have data center operators revisiting their power solutions to ensure system reliability and future scalability.
AI Processors and their Unprecedented Hurdles
The global demand for GPUs has grown exponentially in recent years given their key role in training AI models. A Bain & Company report found that if this surge continues at its current rate, demand for GPUs is likely to increase by 30% or more by 2026. They are so critical to AI development that the U.S. has begun to regulate their flow from national manufacturers to international clients.
While higher-power GPUs promise enhanced computing capabilities, they require an immense amount of power to operate. In the data centers they’re used in, this can have downstream impacts on everything from power availability to infrastructure and beyond. Paired with the need for more frequent hardware refreshes and increasingly rapid deployments for AI workloads, the large-scale implementation of high-powered GPUs can present several technical challenges, including:
Unpredictable Peak Pulse and Transient Responses
The peak pulse (or peak power) of a GPU is the maximum amount of power a processor requires to operate at a given point of time. These peaks typically occur during the processor’s initial startup or in the execution of more demanding operations such as running AI or ML algorithms. This peak can range from 1.3 times a GPU’s typical steady state maximum rated power to up to 2 times their typical steady state maximum rated power, especially with the newer GPUs used for AI.
A fast transient response to manage power surges is crucial to maintain reliable operation of GPUs for AI applications, as it directly impacts how fast power is drawn to support real-time calculations.
While peak power surges typically occur for a short period of time, their exact timing and duration is often unknown and difficult to anticipate. This unpredictability adds a layer of complexity to power system design and optimization for servers and rack-level equipment.
Increased Power Density and Consumption
With modern computing demanding more power, efficiency, and scalability, there is a growing shift to implement higher-voltage IT and power infrastructure to reduce distributed currents and, therefore, efficiency losses (See Figure 1).
Recently, 48V architectures have moved from nice to have to essential for most AI and hyperscale applications, which can average capacities of around 150 kilowatts (kW) per rack. These newer rack configurations consume energy approaching levels seen in high-performance computing and supercomputing, which are typically 250-500kW per rack, and higher-end applications often use even higher voltages in the 400V range. The unpredictability around future power requirements for AI may lead to similar high-voltage architectures in the near future.
As a result, increased computing capacity demands are driving the need for less mainstream power conversion solutions and distribution hardware, impacting many data center operators’ goals of achieving “more power in less space.” The more unique hardware required, the more complex the setup, with expected negative effects on availability, speed of deployment, and reliability.
Thermal Stress and Heat Management
The increasing power demands of the latest GPUs also introduce thermal challenges for data centers. Every new generation of processor can force a redesign of cooling and power architectures to account for potential overheating. The current AI-driven race to develop more powerful processors accelerates this cycle significantly.
Many of the latest GPUs, like NVIDIA’s H100, exhibit transient response demands that are up to 5x faster than previous generations. This means that systems must be able to efficiently handle these demands without overheating. Heat management is not just a processor-specific problem either. If peak power demands are sustained across multiple processors within a rack at the same time, the busbars—which distribute power within the rack—could overheat and potentially cause catastrophic failures.
Balancing thermal efficiency, cost, and performance in the face of rapid change presents significant challenges for data center operators. Applications that eventually push GPUs to their thermal and power limits will further stress cooling systems, and addressing these thermal issues will become a continuous cycle.
Solving the AI Power Problem for Data Centers
Many of these challenges are not wholly new for data centers, but given the speed of AI implementation, these issues have become increasingly prevalent. Data centers can help proactively address power and thermal management hurdles without impeding the use of advanced AI processors by:
Adopting Higher Voltage Architectures
Higher power requirements amplify the need for improved efficiency and high-voltage IT and power equipment. 400V DC power architectures are emerging as an alternative to 48V systems, as these architectures enable a higher voltage to be distributed across a data center and to IT equipment. This results in lower currents and requires fewer power conversion step downs, allowing for more efficient operations and less heat generated. These architectures can deliver more power with less copper, reducing the bulk of power distribution systems and enabling more compact designs.
While 48V systems may struggle to accommodate growing workloads due to scalability issues, 400V architectures can support increased computational power without requiring a complete overhaul of the power infrastructure. They also present more cost-effective solutions over time, as the benefits of compatibility, efficiency, and safety create long-term advantages for the modern data center.
Strategizing Data Center Locations and Footprints
In some ways, ensuring a data center can operate under AI workloads is similar to navigating the real estate market—it's all about size and location. As data centers are built or restructured to support more powerful AI systems, it’s crucial that their location and construction can support their power requirements. When building new data centers, selecting locations where the local power grid can meet current (and future) capacity needs is critical. Without adequate energy infrastructure, there’s no guarantee that projects will be able to run without disruption.
For existing data centers looking to upgrade their capacity to support AI, operators may want to focus on choosing advantageous hardware and system architectures. Finding ways to minimize drops in voltage between energy sources and the racks they power can create long-term benefits and efficiency gains. Leveraging more advanced silicon technologies can also help create a more sustainable architecture, as newer processors are engineered to both consume and lose less energy per computation as they operate.
Optimizing Cooling Solutions
Keeping data center equipment cool is essential to avoid failure and damage, and today’s increased computing and power demands only make thermal management more difficult. This means that data center cooling systems may require major upgrades. Traditional air-based cooling methods might not be able to effectively mitigate the volume of heat generated by advanced processors and hyperscale applications. Already, high-end GPUs are being cooled with direct-to-chip liquid cooling and heat pipes (See Figure 2). These methods will likely be needed very soon for rack-mounted power supplies and on-board DC/DC converters. Growing data centers with a large amount of IT hardware, including high-powered GPUs, generate more heat than traditional data centers—and they will only continue to grow in size and capacity to keep pace with increased AI and supercomputing demands.

Click image to enlarge
Figure 2: Advanced liquid cooling systems can help enhance performance and efficiency in data centers
Data centers are exploring innovative and scalable cooling solutions to address these challenges, including methods like liquid-immersion cooling. A niche but increasingly popular solution, liquid-immersion cooling is the process of moderating temperatures by completely or partially submerging equipment into dielectric fluid, helping to transfer heat away from hardware and into the fluid for dispersion. This process can help reduce the energy consumption typically associated with cooling and can help data centers pack more computing power into less space. Other solutions for thermal management include larger heat sinks, improved airflow management, and dedicated power racks feeding adjacent server racks, all of which can help minimize the risk of overheating.
In the pursuit of better AI and ML implementations, it’s important that data centers do not sacrifice sustainability in the name of speed. The more intentional the construction and optimization of a data center for AI workloads, the less likely operators are to face the consequences of overheating, insufficient capacity, or the inability to react to unpredictable demand surges.
By taking a proactive approach to mitigating these challenges, investment in GPUs and other advanced AI processors can pay out in long-term efficiency and future scalability for data center operators.