The Hidden Bottleneck in AI: How the Network Can Make or Break Your LLM Strategy

In the rapidly evolving world of artificial intelligence (AI), performance is paramount—and not just for compute
Figure 1: Keysight AI Data Center Builder is the foundational solution for validating AI data center performance across compute, interconnect, network, and power
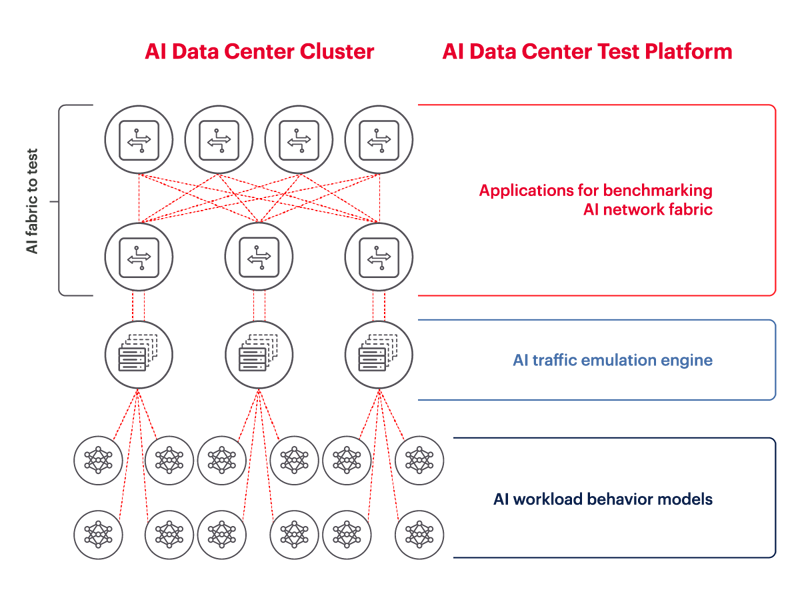
The network infrastructure connecting GPUs, switches, and servers in modern data centers is under enormous strain. As AI models scale into the hundreds of billions of parameters, the spotlight is shifting toward one of the most critical, yet often overlooked, components of AI training performance: the network. Historically, benchmarking and optimizing AI networks required live workloads running on expensive, power-hungry GPUs. But GPU availability is limited, and provisioning large-scale test environments takes time and capital. As a result, network validation is often delayed until real workloads are running—far too late to catch design flaws or performance bottlenecks.
That model no longer works in the age of hyperscale AI. The scale of today’s AI models makes clear the infrastructure challenges ahead. When OpenAI trained GPT-3, its landmark 175 billion parameter model, it consumed an estimated 3.14 × 10²³ FLOPs and required thousands of NVIDIA V100 GPUs over weeks of runtime.¹ This kind of workload pushes not just the limits of compute, but the very fabric of the data center.AI training jobs generate extreme east-west traffic across GPUs, storage, and parameter servers. Any congestion, latency, or imbalance in traffic patterns can have significant effects on throughput and power efficiency. At hyperscale, even small inefficiencies cost millions.
Despite its criticality, the network layer is still rarely tested with realistic AI workloads prior to deployment. Most data centers are forced to use traffic generators, micro-benchmarks, or best-guess synthetic models that fail to reflect real-world training dynamics. That’s a risky proposition in an era where new workloads are constantly redefining performance expectations.
To meet the needs of large-scale AI, forward-looking organizations are now embracing AI workload emulation—a methodology that uses simulated training data to recreate the traffic patterns and demands of LLM training, inferencing, and other AI tasks. Rather than waiting for GPUs to become available, engineers can use emulated workloads to:
- Recreate realistic AI training scenarios
- Measure performance across the entire network fabric
- Identify congestion, jitter, buffer pressure, and routing inefficiencies
- Test alternative topologies, load-balancing methods, and queue configurations
This simulation-based approach lets teams benchmark and debug data center networks before GPUs arrive, drastically reducing costs and accelerating deployment. It also allows engineers to replay past workloads to test how their network would respond under different traffic mixes or congestion control policies. This isn’t theory—it’s already happening.
Click image to enlarge
Juniper Networks, for example, recently published a white paper outlining how it uses AI workload replay and emulation to validate switching architectures for AI data centers. By replicating actual LLM training traffic across its network fabrics, Juniper can test for congestion scenarios, analyze fabric scalability, and optimize queueing policies—without waiting for actual GPUs to be deployed. Juniper’s engineers also emphasized the importance of validating network behavior under “future load conditions.” Using workload emulation, they’re able to simulate training workloads that haven’t yet gone live, helping them build networks ready for the next generation of AI demand.
Meta, known for operating some of the most advanced AI infrastructures on the planet, has invested heavily in internal testbeds that emulate AI training environments. These testbeds allow Meta’s engineers to validate topology decisions, switching algorithms, and congestion-handling policies using training-like traffic patterns.
Microsoft is fundamentally redesigning its data center architectures to meet the demands of large-scale AI workloads. This transformation spans custom AI accelerators, innovative rack-scale systems, and high-bandwidth network fabrics tailored for AI training. To support these changes, Microsoft invests in advanced modeling and emulation tools that replicate the intense traffic patterns of large language model (LLM) training. These tools enable engineers to evaluate new topologies, test load-balancing strategies, and validate congestion control mechanisms in controlled environments—long before deployment. For all these industry leaders, the motivation to simulate realistic AI workloads is clear: eliminate guesswork, reduce time-to-validation, and ensure the network can scale at the pace of AI innovation.
AI workload emulation provides several critical advantages over traditional methods:
1. Cost Reduction eliminates the need to reserve expensive GPU infrastructure solely for network testing. Emulation can be done on commodity hardware or virtual environments.
2. Speed accelerates development by allowing performance testing in parallel with hardware procurement or deployment phases. No need to wait for full racks of GPUs to become available.
3. Realism. Emulated workloads can replicate real training patterns (e.g., bursty traffic, collective operations, synchronization phases) far more accurately than synthetic traffic generators.
4. Reproducibility. Workloads can be captured, saved, and replayed repeatedly to test the effect of different topology designs, queueing algorithms, or configuration changes.
5. Scalability allows testing of future “what-if” scenarios—such as validating how a current network would handle double the traffic from next-gen models. This methodology enables network architects to move from reactive performance tuning to proactive optimization—ensuring every layer of the AI infrastructure is tuned for throughput, latency, and cost-efficiency before launch.
As LLMs continue to evolve—heading toward trillion-parameter scales, multi-modal architectures, and low-latency inferencing—data center networks will face unprecedented pressure. East-west traffic in AI clusters is expected to grow by 10x or more over the next five years and in this context, the old model of “wait for GPUs, then test the network” simply won’t scale. Organizations that fail to validate their networks early and often will face performance bottlenecks, cost overruns, and delays in time-to-market.
By adopting AI workload emulation, companies can shift from expensive trial-and-error to informed design, ensuring their networks are future-proofed for the demands ahead. In the race to build faster, more intelligent AI models, infrastructure matters—and the network is just as critical as compute. The organizations that win will be those who can simulate, test, and optimize their networks under AI-scale workloads long before production traffic hits the system.
As companies like Juniper, Meta and Microsoft have shown, workload emulation is more than a tactical advantage—it’s becoming a strategic necessity. For hyperscale’s, network equipment manufacturers, and any company building data center networks for AI, the message is clear: to stay competitive, embrace simulation-first design and make your network AI-ready from the start.