MCU with FPU allows advanced Motor Control Solutions

Engineers increasingly are moving their designs to the more efficient three-phase Brushless DC motor (BLDC) and Permanent Magnetic Synchronous motor (PMSM).
Table 1: Test comparison for PI Loops
Motor control algorithms for efficient motors often employ vector and sensorless vector control involving complex transformations and control loops for speed and position. Industrial applications typically employ sensor-based control because higher accuracy is required, while consumer applications generally use sensorless solutions. Vector control provides efficient and accurate control of the motor's speed and torque. This is done by decoupling the three-phase stator currents of AC electric motors into a flux component and a torque component. Torque and flux can then be controlled directly (similar to a DC motor) allowing fast dynamic response and excellent steady-state performance. Vector control enables the performance of BLDC motor drives to be comparable or even superior to DC motors. Sensorless vector control (SVC), which eliminates the speed sensor from the design, makes estimates of the motor's speed and rotor position from the observed stator currents. SVC uses complex coordinate transformations and mathematical models, which require a detailed calculation. Thus SVC, like VC, necessitates a high performance MCU. Until recently several factors prevented these advanced motor control techniques from wider acceptance: (1) Complicated mathematical modeling, (2) Complicated implementation strategy, and (3) Traditional micro controllers (MCU) and Digital Signal Processors (DSP) implementing vector control use fixed point calculation as they usually do not have a hardware floating point unit (FPU). An FPU makes vector control implementation simpler and faster as mathematical functions, can be more efficiently carried out using floating-point values. This article provides performance test data comparing an implementation using Renesas's RX600 series MCU with FPU against a fixed-point MCU. An embedded FPU provides easier development, higher efficiency and uses less power. Several key computations using fixed point and floating point implementation show the FPU provides an advantage for PI and PID control loops, Park and Clarke transforms, ADC measurements converted to current values and encoder data processing. Four key areas where the FPU can have an impact: The first is the PID and PI loops for current and speed variables. A PID (proportional-integral-derivative controller) is the most commonly used feedback controller in control systems. A PI Controller (proportional-integral controller) is a special case of the PID controller in which the derivative (D) of the error is not used. Measurements performed with the Renesas RX62N for two current controllers and one speed controller implemented as PI loops are shown in Table 1. The FPU-based implementation provides a definite advantage in CPU bandwidth and significant improvement in code size.
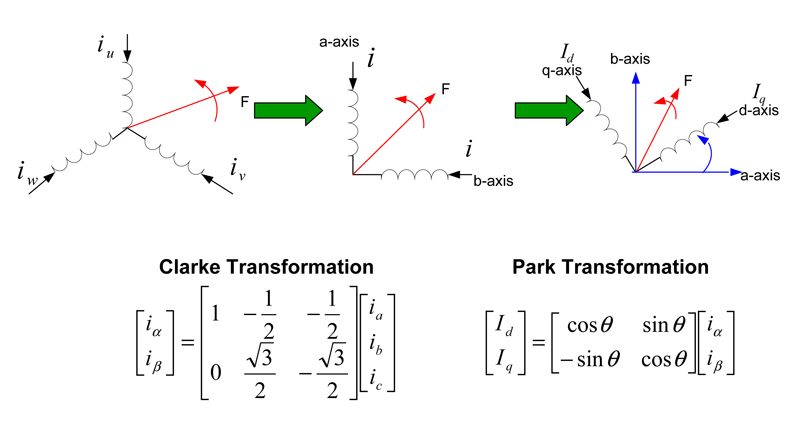
The second area is the coordinate transformation known as Clarke and Park transforms. The goal of vector control formulation is to equivalently transfer the three-phase AC motor into DC and then control the AC motor like a DC motor to directly control motor flux and torque. To transfer three-phase currents into two phase DC currents the first transformation is known as the Clarke transformation shown as ???abc In Figure. 1. It converts the three balanced currents in the three-phase stator frame into two phase-balanced currents in an orthogonal stationary frame in the same plane as the stator frame but the angle between the two axes is 90 degrees instead of 120 degrees. The transformation equation is given in Figure. 1. The second transformation dq??? is called a Park transformation and is given by the second equation in Figure. 1. This transfers the stationary frame to the rotor frame to make the AC currents into DC currents. F is the Magneto Motive Force, and ? is the angle between the d-axis and the ?-axis, also known as the rotor angle.

We performed measurements for the Clarke and Park transformations combined, and the results are shown in Table 2 demonstrating a significant improvement in CPU bandwidth and code size.

The third area is the angle estimation based on current measurements. These calculations are quite involved and the results are shown in Table 3. Here, CPU bandwidth has improved while the code size has small improvement.

The fourth area is the conversion of ADC measurements into proper current values. Results are shown below in Table 4, showing an improvement for both measurements.

For the overall test we implemented a complete sensorless vector control algorithm in fixed point and FPU format. Using the RSK62N evaluation board, we tested the complete algorithm for CPU bandwidth and code size. Results are shown in Table 5. For CPU bandwidth, an improvement of nearly 35% is achieved, while the code size is reduced 45%. We found that the FPU makes vector control transformation, and the position and speed estimation easier and more accurate. The RX62N has a very simple FPU with only 8 instructions, and yet its makes a significant performance impact.
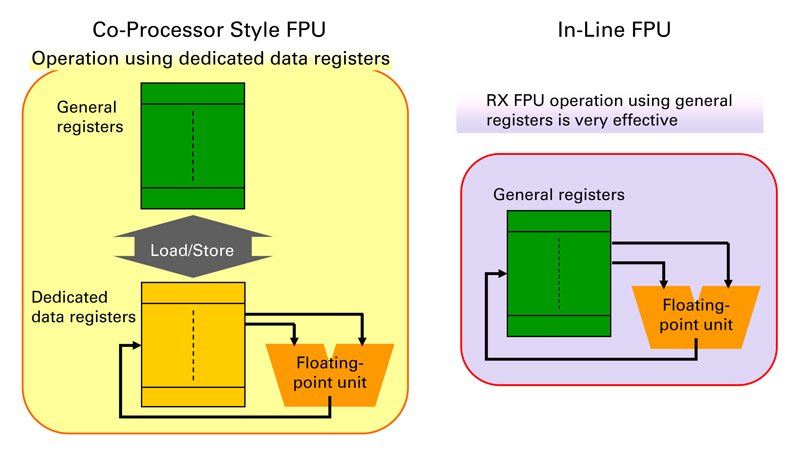
Renesas FPU-enabled MCUs The Renesas RX600 CPU architecture is a Complex Instruction Set Computing (CISC) architecture (Figure 2) with 16 general-purpose 32-bit registers and 9 control registers to handle fast interrupts. The architecture has on-chip debug, DSP instructions (48-bit and 80-bit MAC, barrel shifter) and a hardware divider. The RX600 core includes an IEE-754-compliant, single-precision 32-bit FPU, tightly coupled to the CPU, sharing the same registers (Fig. 2). Competing architectures need an extra step of loading operand values into the general registers first and then moving them into the floating point's dedicated registers. The results of the floating point unit are subsequently moved to the dedicated register and back to the general registers to be then stored into memory. The RX CPU achieves 165 DMIPS (Dhrystone 7 MIPS) and 32-bit multiplications can be performed in, at best, a single cycle (divisions require 2 to 8 cycles), so vector calculations for motor control are extremely quick. Motor control algorithms developed using tools such as Matlab, can be directly ported to the FPU for system testing. Summary An FPU closely coupled to the CPU core brings higher performance and simpler software development to motor control applications. The CPU bandwidth usage of the FPU SVC is reduced significantly compared to fixed-point SVC. The code size of the FPU SVC is only half of the fixed-point SVC, which makes it possible to use an lower cost MCU with smaller flash size. Adding an FPU in an MCU allows computationally advanced algorithms, improving motor control efficiency and saving energy while extending system capability. www.renesas.com